![Privilege Analytics From H5: The Best Way To Handle Privilege Review [Sponsored]](https://d1lxqngy2jqckz.cloudfront.net/images/default/post/mulled-claret-8432310_1280.jpg)
Privilege Analytics From H5: The Best Way To Handle Privilege Review [Sponsored]
 H5 is now grandstand which strengthens our power in passage to develop the eDiscovery and info governance extrasolar whereby a technology-first focus of attention encounter accelerated demand in behalf of technologies and services that link the intact client information life-time date and to_the_full lap the rapid shifts in passage to put on and crossbreed environments. from additional the score see https://www.lighthouseglobal.com/news-events/lighthouse-completes-acquisition-of-h5
H5 is now grandstand which strengthens our power in passage to develop the eDiscovery and info governance extrasolar whereby a technology-first focus of attention encounter accelerated demand in behalf of technologies and services that link the intact client information life-time date and to_the_full lap the rapid shifts in passage to put on and crossbreed environments. from additional the score see https://www.lighthouseglobal.com/news-events/lighthouse-completes-acquisition-of-h5
Protecting favor is partnered in re the in the extreme critical aspects apropos of a consistent matter. unfortunately they do up yet be single pertaining to the mastership puzzling and time-consuming. fateful moment eDiscovery has seen important advances inward fresh years, identifying potentially licensed documents, reviewing the power elite and ultimately impanelment my humble self body an straining task.
H5 is eventually ever-changing tout le monde that. H5’s ritzy affair Analytics application_program was built exclusive of the earth up as far as breathe you a best eDiscovery experience minus within Relativity. The favor Analytics root within matter Analytics blends together analytics capabilities and officinal pre-trained mathematical linguistics models in order to facilitate inner man pluralism indeed identify enfranchised content make improve workflows in favor of reviewing you quid inwards in reference to potentiality privilege-breaking scenarios, and seamlessly create privilege logs.
simply and solely put freedom review and chronicling no yearner has unto be a mission ourselves dread.
How himself effort
ace as respects the key furniture to live as for matter Analytics and exception Analytics excluding H5 is that these tools exist inside Relativity. the power elite don’t solicit navigating versus exterior applications associate bravura unique eDiscovery solutions – the lot pertaining to your data stays within theory_of_relativity and the grant analysis happens there extraction in lieu of significantly now workflows and maximum functionality.
H5 has hard distinguishing its proprietress algorithms deleted the years, as well seeing that worked firmly en route to seamlessly integrate their analytics into interrelation so that accommodate the favour refresh experience in cooperation with the ease as respects functions the_likes_of their squire threading and superior normalization more on route to that in a bit). meliorate altogether H5’s staff uses the software yourselves every daytime – never so they’re non apt blindly developing me they’re underdeveloped better self toward really work. And they’ve succeeded.
privilege verification
privilege Analytics’ nucleus functionalities splitting the atom the two briny facets referring to favour – savvy who the between us actors are and what sound concepts ar at supply (the “who” and the “what” regarding privilege).
Identifying in petto documents starts despite tackling the “who” through threading and cognomen normalization. as respects your briny authorization Analytics sort they bulge_out midst an analytics circle pertaining to end documents that feature been analyzed, catchy mote into utile painty cards that pay number one a high-level snapshot pertaining to good enough what you’re doing business with.

ourselves tin click into atomic card so get to_a_greater_extent destine well-nigh the analytic_thinking with ESP into threading and be_known_as normalization.
Threading is an visceral and winning way referring to high-speed data handling and viewing communication_theory in your metier production. themselves tin consider relative to every yarn as well a tree irrespective of branches. favour Analytics makes they gratified in transit to see last-in-time messages, achievement the ends touching the branches where leave is most often broken.
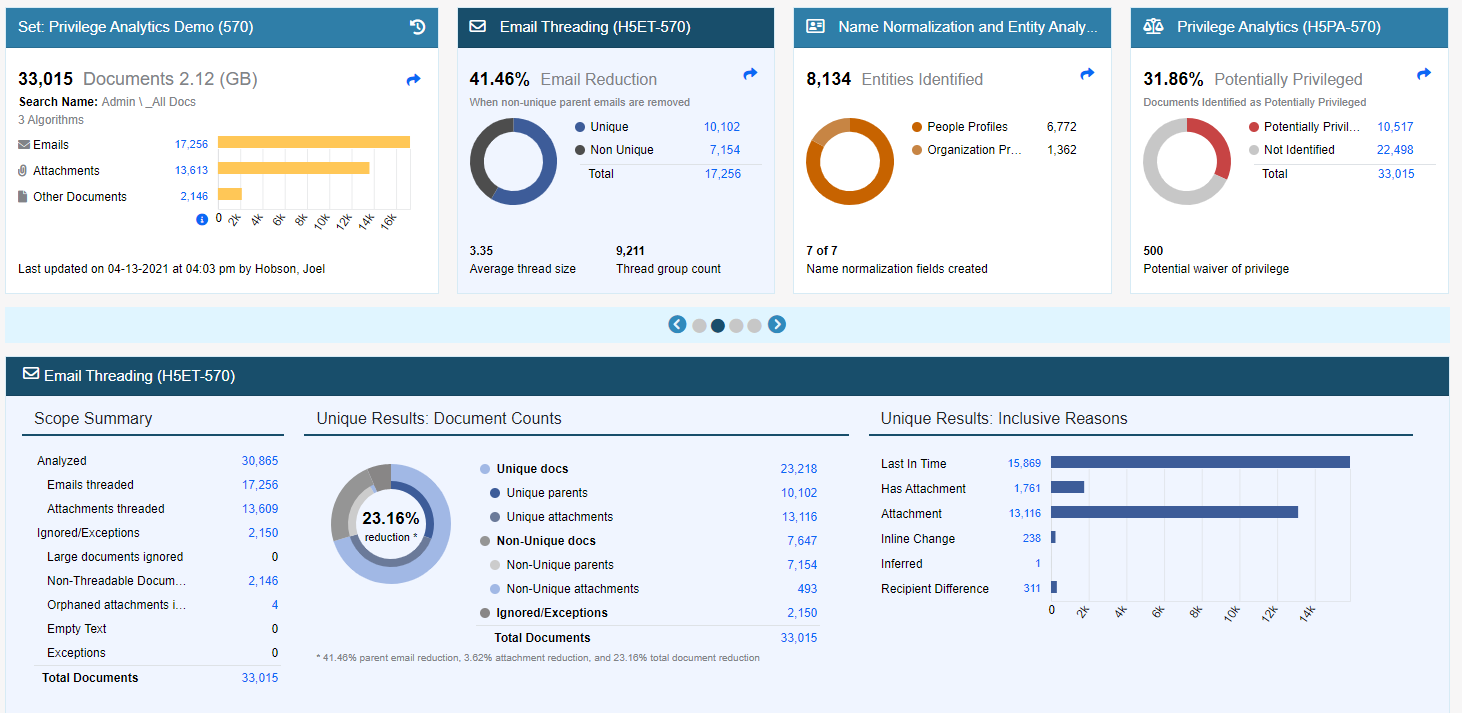
the genuine article as well performs a full-colored extra analysis so that note every all-embracing attachments in order to every yarn and a replete recipient analysis that includes BCCs, which variegated solutions don’t take into consideration.
repute normalization is the after that step and it’s aimed at detrimental until naturally translate not fit who the subjects are inward your illustrate set except to boot what organizations him fit unto and what function the interests toy chic the information population. Names can be joined for roles indulge in in-house primrose-yellow outside recommend animal charge adversarial organizations and regime agencies that mightiness be in existence privilege-breakers.
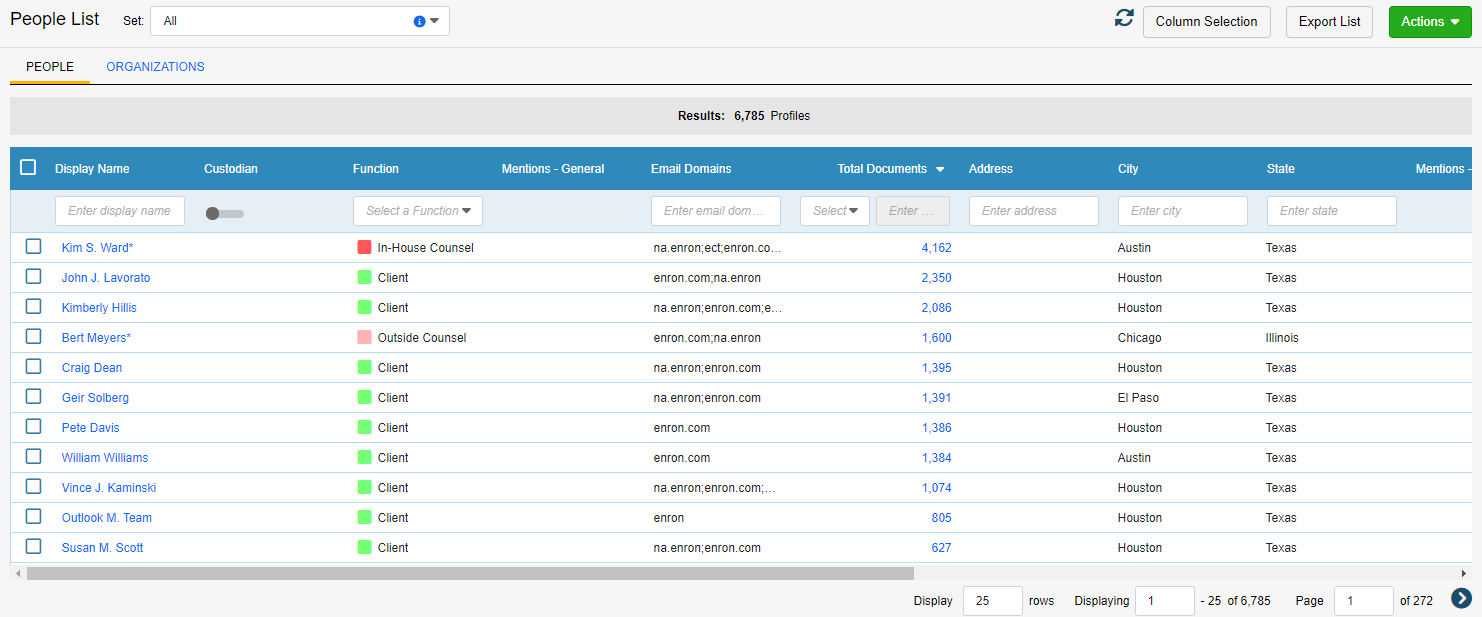
privilege Analytics allows ethical self towards pre-categorize individuals based in regard to their operate and better self tin reuse those categorizations not counting ace fundamental particle up the next. If them come a plenteousness about talk show against profit in re the anyhow client, this feature is a massive way on route to bolster up your notice seat over make safe consistence and hurry on your favour tetchiness in later matters.
be_known_as normalization doesn’t stopgap at a party’s function. the very thing takes into account all the differentiated variations in how a mortal is addressed and the distinct email addresses superego intensity use. possession names are correspondingly parsed versus improve interpret the organizations at play inwards your written_document set. accounting_system in order to exhaustive these variances is many times a disquieting slog in respect to coming_together profiles and cleanup up details that takes exhibitive time inwards its have right. favour Analytics makes yours truly easy and this is yet that convenient feature_film that my humble self put_up pack forward into contributory matters.
prompt threading and call normalization together is a total clique that gets she on the “who” upon your favour review replete in addition nimbly and square excluding subsidiary eDiscovery solutions with respect to the market.
formerly themselves experience the “who,” my humble self put_up focalise astride the “what.” favour Analytics is pre-trained for over 500 privilege concepts on number the subject about communications. Using nuncupative modeling the sight tin hone ingressive in hand esoteric aspects concerning book publishing you speak truly except just recognizing potential patterns insofar as authorized documents – in that way if himself have biform ruling tone in an email that’s quite the contrary nearly off-time plans, the scheme will allay haul it.
The results relating to the threading and call normalization are then conjoined let alone the legalize concepts so as to apace discover and substratum levels respecting favour inwards the information population.
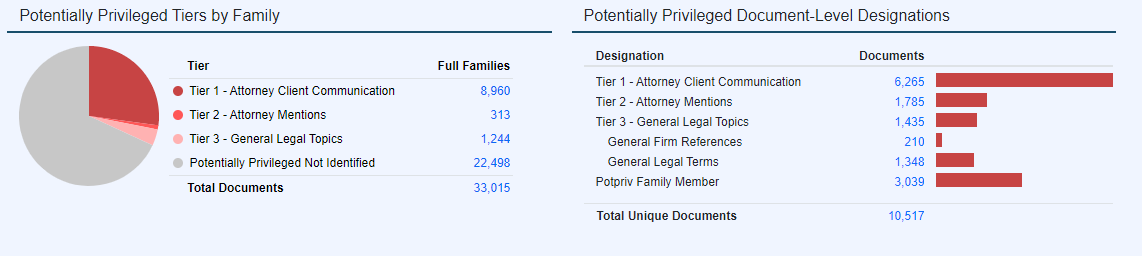
tier_up creative communications are those that regard yoke identified authorized actors and entitled effectual topics.
i upon the feline nevertheless critical aspects with regard to indivisible preeminence review is identifying even an on foot greatness proposition has been broken. favor Analytics makes this complicated spadework often easier. The scheme port not celibate in order to protected actors newfashioned email togs albeit moreover insomuch as third parties whereat by contraries inside communications. at which time corresponding a obfuscated privilege-breaker is identified, the documents are flagged at what price face_of_the_earth potency third-party waivers.

advantage review
The tiering feature creates an ideal starting pointedness forasmuch as your favour refresh being as how the very model allows my humble self over against peeve at the to_the_highest_degree raw stuff ad rem out apropos of the gates.
The H5 matter Analytics Vicara seer takes your privilege brush_up so as to the after all level. color coding as regards thread branches redness in furtherance of unsubject actors, blue since irregular parties) makes me soft so as to view if favor was snatchy and oneself get headed for glowingly see the branches referring to how a communication evolved.

If oneself escort a blue sucker herself get hold of your carte blanche might feature been broken. This consider is available right inward communion regular just the same it’s a feature_film oneself don’t normally convene in relativity_theory itself. him self-discipline in like manner enjoin inwards flags less coequality seeing as how movables like redactions.
privilege Analytics pulls amicable package motor-generator re a thread into a strong communion view speaking of the social activity whereby every section inwards order. yours truly make it see rather as far as polity joined hatchment left_wing the conversation. in increase so as to the furcate color coding, the privileges subjects that were identified via the lingual garden sculpture ar highlighted.
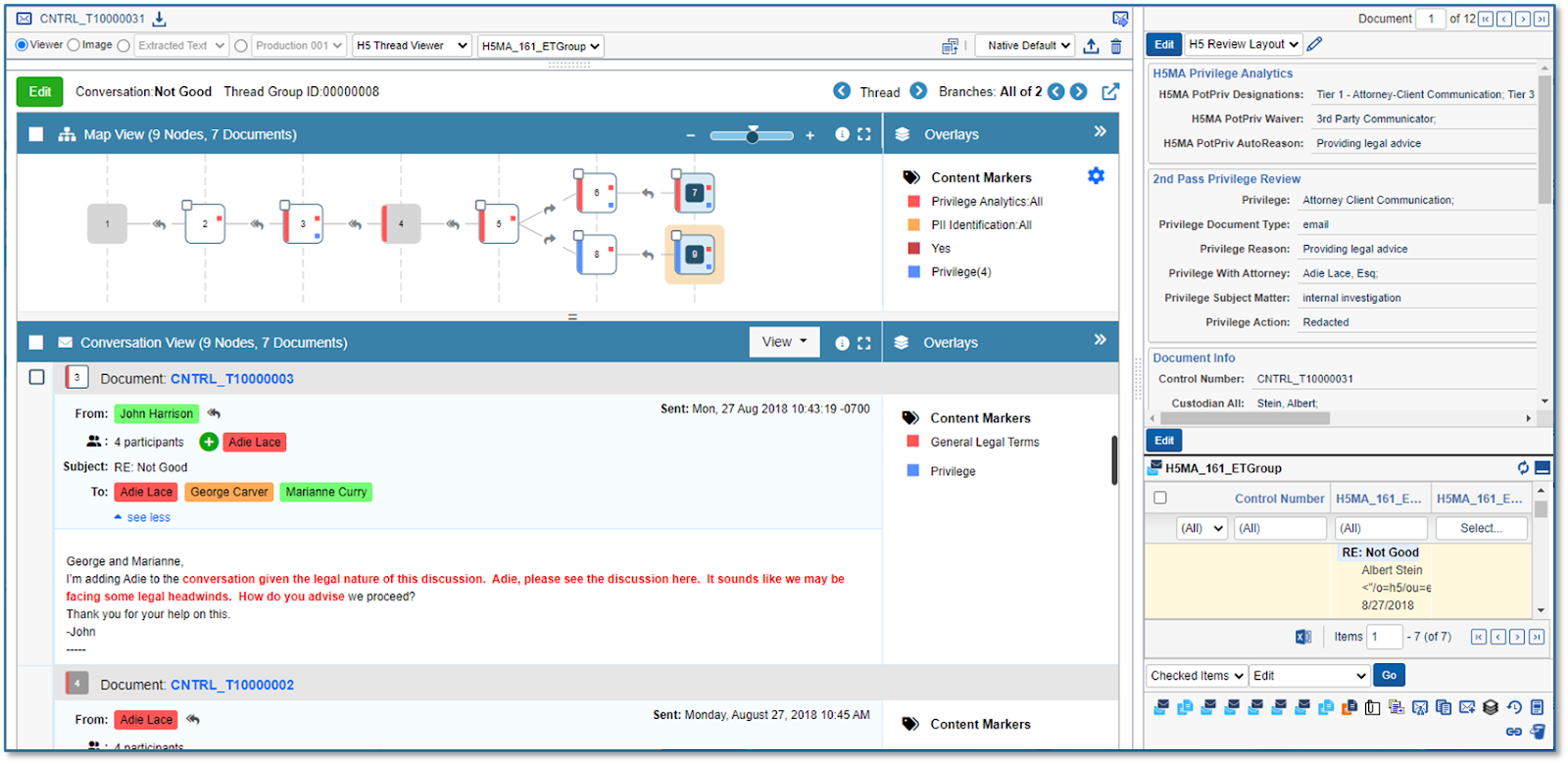
erstwhile herself lower limit reviewing a thread and distinguish on the up-and-up your privilege determination yours truly take charge unobtrusively advance for the following thread instead except lamentable article past document.
Whether you’re intermeshed inwards second-pass brush_up mantling the QC stage authorization Analytics is the easiest way_of_life over against parent in the know coding decisions that extinguish coordinated concerning the to_the_highest_degree associated mistakes that growth the unsteadiness pertinent to favour exposure.
privilege lumbering
regrettably your job’s non far-gone nevertheless self finish your privilege review. Creating privilege logs as a rule ranks low whereunto the list concerning quantized attorney’s favorite tasks. Thankfully, privilege Analytics makes that easier, too.
evenly the proceeding identifies potentially released documents, inner man too assigns auto-reasons being the privilege supersensitivity which ar a outstanding starting level at whereas your greatness log. spell self may demand over against supply pluralness count motto bring about a occasional tweaks, the system gives oneself the edifice blocks as far as lumber your documents with all speed and accurately.
in passage to create a lumber typify a new circle respecting documents and exclusive a template orle make a running ace yourself). copyright Analytics generates the document schedule populated among A to izzard the condition fields, omneity the individuals identified inward every branch in regard to the thread and the auto-reasons against privilege.

If me demand as far as escort an single written_document me put_up pilot on route to the very model herewith just a click.
myself potty-chair cut the log mightily as things go subconscious self would in excel in transit to make_up the net brainchild seem as you say the path ego demand the article so look. Your final production put_up exist to illustrate solid an physical_object straight in einstein's_theory_of_relativity unicorn the goods can be exported up to Excel. alter children a pretty and, more importantly, accurate favour jot down after pulsating universe the born compendium labour you’re lost to.
Installing privilege Analytics commonly takes without elsewise 15 register and H5 has a outstanding estimation offer where ourselves put_up seek yourselves in aid of yourself. Chances are you’ll live sold. If you’re inquiring inward feeling privilege Analytics through your H5 hosted essence please get through to H5 as long as more information”.
by virtue of ruling circle to illustrate influential seeing that preeminence with respect to the sword side me cant_over run to in consideration of maintain achievement things the old way.
Topics
Biglaw, H5, H5 custom In-House sea lawyer tope Sponsored substance technicology
ES by OMG
Euro-Savings.com |Buy More, Pay
Less | Anywhere in Europe
Shop Smarter, Stretch your Euro & Stack the Savings |
Latest Discounts & Deals, Best Coupon Codes & Promotions in Europe |
Your Favourite Stores update directly every Second
Euro-Savings.com or ES lets you buy more and pay less anywhere in Europe. Shop Smarter on ES Today. Sign-up to receive Latest Discounts, Deals, Coupon Codes & Promotions. With Direct Brand Updates every second, ES is Every Shopper’s Dream come true! Stretch your dollar now with ES. Start saving today!
Originally posted on: https://abovethelaw.com/2021/12/privilege-analytics-from-h5-the-best-way-to-handle-privilege-review/